ロジスティック回帰分析について。
【目次】
今回はモデル作成まで。モデルの評価は別記事で。
計算式等
ロジスティック回帰は二値分類()で用いられる分析手法。
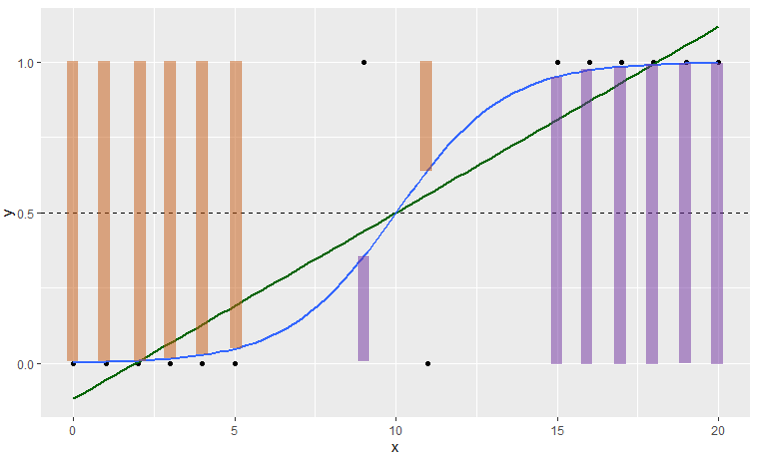
モデル式は回帰分析と似ているが、シグモイド関数を使って0~1の範囲の結果を出すことが特徴(通常の回帰分析では0~1の範囲を超えてしまい、解釈不能な結果になってしまう)。
(青線:ロジスティック回帰、緑線:単回帰分析)

モデル式、シグモイド関数および損失関数はそれぞれ次のとおり。
モデル式
シグモイド関数(活性化関数)
交差エントロピー誤差(分類問題の損失関数)
※ ln( ) は自然対数。 は実測値で
です(正解ラベルとも言われます)。
交差エントロピー誤差は、対数尤度にマイナスをつけて0を最小値としたもの(負の対数尤度)。式の第一項( )で実際にイベントが起きたデータ(
)に対する予測誤差を計算する(予測90%なら10%が誤差)。式の第二項(
)でイベントが起きなかったデータ(
)に対する予測誤差を計算する(予測10%なら10%が誤差)。
第一項も第二項も の時に
となることから、実測値と予測値が完全一致すれば合計0で誤差なしとなる。
※イメージ的には紫の棒が の時の
、オレンジの棒が
の時の
。
対数尤度関数の計算方法についても掲載。
対数尤度関数
尤度関数
※尤度関数は0~1の確率を "かけ算" するため、値がかなり小さくなってしまう(コンピュータ計算に不向き)。そのため、対数変換して確率の "足し算" とした対数尤度関数が広く使われる。
そして、肝心の回帰係数 β の計算方法は次のとおり。
回帰係数 β の計算方法
式中に があるため、"回帰係数 β を算出するために回帰係数 β が必要" ということになる。本記事ではニュートン・ラフソン法(以降、ニュートン法)による回帰係数の更新方法を取り上げる。
ニュートン法では既存の回帰係数 と演算後の回帰係数
との差がなくなるまで更新を繰り返す。最適解の算出には交差エントロピー誤差のヘッセ行列(H)と重み付き行列(R)を用いる。このRはシグモイド関数の微分の対角行列。
これらをまとめると次の図解。
近似的な方法
簡易的にロジスティック回帰分析を行う方法として、ロジット変換した値を目的変数にした回帰分析がある。二値を Yes / No の数で表すとロジット変換は次の式。
なお、0の対数変換 は計算できないため、0.5 を加算してロジット変換する方法がある。これを経験ロジットと言う。
また、この回帰分析に重みを加えたい場合、ロジットの分散の逆数を重みとする(重み付き回帰分析)。経験ロジットを使う場合は3つ目の式。
最後に、覚えておくと良さそうなシグモイド関数の性質をメモ。
シグモイド関数の性質 ←オッズ比
ノート
今回も簡単なデータで計算手順を見てみる。
■ サンプルデータ
| X1 | X2 | Nyes | Nall | Pyes | Logit | 経験Logit |
| 5 | 0 | 1 | 20 | 0.050 | -2.944 | -2.565 |
| 5 | 1 | 6 | 22 | 0.273 | -0.981 | -0.932 |
| 10 | 0 | 9 | 25 | 0.360 | -0.575 | -0.552 |
| 10 | 1 | 16 | 30 | 0.533 | 0.134 | 0.129 |
| 15 | 0 | 19 | 30 | 0.633 | 0.547 | 0.528 |
| 15 | 1 | 28 | 30 | 0.933 | 2.639 | 2.434 |
今回は近似的な方法で算出した回帰係数 β を初期値にする
その後、ニュートン法を用いて回帰係数 β を更新し、最適解を探す。
初期値設定

LINEST関数で計算。目的変数は経験ロジット。今回は重み付き回帰分析はしていない(単に初期値を得るためなので)。
回帰係数 β はそれぞれ 。
※LINEST関数の使い方は単回帰分析で記載。
回帰係数 β の更新1回目

初期値の回帰係数 β をもとに予測値 を算出する。
サンプルデータの1行目は なので次のとおり。※上図Excel A列の
は切片項用に 1 を設定。
次にヘッセ行列を求める。
<式の再掲>
サンプルデータの1行目を取り上げると R は 。
ヘッセ行列は次のとおりで、今回は切片+説明変数2つの3次元なので3×3の行列になる。
※ 今回の集計表はレコードをまとめているため、計算式に「 」を入れている。
さらに を求める。
※ 今回の集計表はレコードをまとめているため、計算式に「 」と「
」を入れている。「
」は
の時だけ0以外の値を持つため「
」としている。
これら計算結果から回帰係数 β を更新すると次のようになる。
それぞれの更新前後の差は 0.00306, 0.00198, 0.08494 で差があるので更新を続ける。
回帰係数 β の更新2回目

更新2回目は で更新前後の差は 0.00508, -0.00043, -0.00206 。だいぶ良くなったが、まだ差があるので更新する。
回帰係数 β の更新3回目
 更新3回目は
更新3回目は で更新前後の差は 0.000000, 0.000000, 0.000000 。更新前後の回帰係数 β が同値で差がなくなった。
よって更新はここまでにして次を最終モデルとする。
Rでの実行:
> ads <- data.frame(
+ x1=c(rep(5,20),rep(5,22),rep(10,25),rep(10,30),rep(15,30),rep(15,30))
+ ,x2=c(rep(0,20),rep(1,22),rep(0,25),rep(1,30),rep(0,30),rep(1,30))
+ ,y=c(rep(0,19),rep(1,1),rep(0,16),rep(1,6),rep(0,16),rep(1,9),rep(0,14),rep(1,16),rep(0,11),rep(1,19),rep(0,2),rep(1,28))
+ )
> fit1 <- glm(y ~ x1 + x2, family=binomial, data=ads)
> summary(fit1)
Call:
glm(formula = y ~ x1 + x2, family = binomial, data = ads)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0812 -0.8307 0.4935 0.8906 2.2684
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.10022 0.72055 -5.690 1.27e-08 ***
x1 0.32135 0.05562 5.778 7.58e-09 ***
x2 1.32386 0.40344 3.281 0.00103 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 217.64 on 156 degrees of freedom
Residual deviance: 164.56 on 154 degrees of freedom
AIC: 170.56
Number of Fisher Scoring iterations: 4
SASでの実行:
data ads(drop=i); do i=1 to 1; x1= 5; x2=0; y=1; output; end; do i=1 to 19; x1= 5; x2=0; y=0; output; end; do i=1 to 6; x1= 5; x2=1; y=1; output; end; do i=1 to 16; x1= 5; x2=1; y=0; output; end; do i=1 to 9; x1=10; x2=0; y=1; output; end; do i=1 to 16; x1=10; x2=0; y=0; output; end; do i=1 to 16; x1=10; x2=1; y=1; output; end; do i=1 to 14; x1=10; x2=1; y=0; output; end; do i=1 to 19; x1=15; x2=0; y=1; output; end; do i=1 to 11; x1=15; x2=0; y=0; output; end; do i=1 to 28; x1=15; x2=1; y=1; output; end; do i=1 to 2; x1=15; x2=1; y=0; output; end; run; ods output LackFitChiSq=HOSLEM1; proc logistic data=ads descending; model y(event='1') = x1 x2 / outroc=ROC1 lackfit; output out=OutDS; run;

統計ソフトってすごく便利。。と体感した。
プログラムコード
■ Rのコード
fit <- glm(y ~ x1 + x2, family=binomial, data=ads) summary(fit)
■ SASのコード
proc logistic data=[InputDS] descending; model y(event='1') = x1 x2; output out = [OutDS]; run; quit;
■ Pythonのコード
整備中
交差エントロピー誤差の偏微分
回帰係数 β の計算方法で示した交差エントロピー誤差の偏微分の詳細。
「連鎖律」という方法で微分する。
図解するとこんな感じ。シグモイド関数の微分は公式で z(1-z) になる。

-----
なお、SASやRのロジスティック回帰では「ニュートン法」ではなく、「フィッシャースコアリング法」が用いられているようだった(記事を書き終わってから気づいた)。
この方法は、ニュートン法で使った「ヘッセ行列」を「フィッシャー情報行列」に置き換えたもの。計算コストが良い様子。
今回は更新の仕組みが分かれば良いと思っていたため、この記事は終了。
フィッシャースコアリング法について Wikipedia を参照。
参考
多変量解析実務講座テキスト, 実務教育研究所