Kerasの勉強用にロジスティック回帰と同じ構造を作って実行してみる。
【目次】
基本の整理
ニューラルネットワークは入力層ー中間層ー出力層からなり、図示するとこんな感じ。
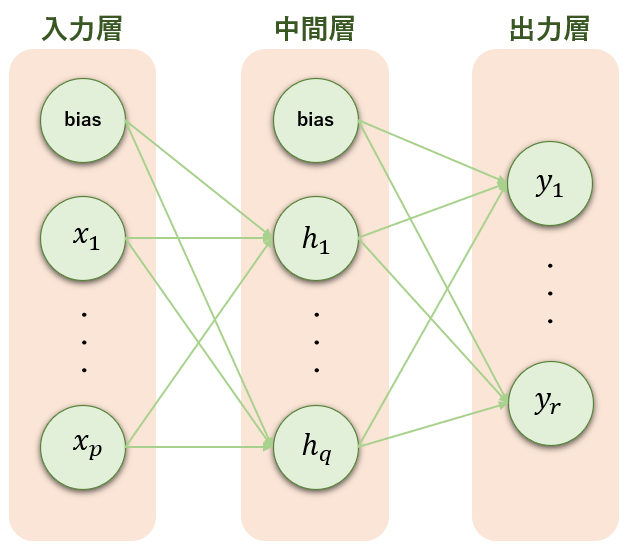
このうち、ロジスティック回帰は中間層がない単純な形。

活性化関数にはシグモイド関数が使われる。
また、損失関数には交差エントロピー誤差が使われる。
使用データ
import numpy as np import pandas as pd from scipy import stats from sklearn import model_selection #-- import train = pd.read_csv("../input/titanic/train.csv") test = pd.read_csv("../input/titanic/test.csv") ###--- 欠損処理 train["Age"] = train["Age"].fillna(train["Age"].median()) #--中央値で補完 train["Embarked"] = train["Embarked"].fillna(train["Embarked"].mode().iloc(0)) #-- 最頻値で補完 test["Age"] = test["Age"].fillna(test["Age"].median()) #--中央値で補完 test["Fare"] = test["Fare"].fillna(test["Fare"].median()) #--中央値で補完 ###--- カテゴリの数値化 train["Sex"] = train["Sex"].map({'male':0, 'female':1}) train = pd.get_dummies(train, columns=['Embarked']) test["Sex"] = test["Sex"].map({'male':0, 'female':1}) test = pd.get_dummies(test, columns=['Embarked']) ###--- データ分割 Xval = ["Pclass", "Sex", "Age", "Fare", "Embarked_C", "Embarked_Q", "Embarked_S"] df_y = train["Survived"].values df_X = train[Xval].values train_X, valid_X, train_y, valid_y = model_selection.train_test_split(df_X, df_y, random_state=19) test_X = test[Xval].values
Keras での試し書き(モデル作成)
先ず下準備として乱数シードを固定する。
また、データを標準化した方が精度が良かったので標準化。
import pandas as pd import numpy as np import tensorflow as tf from keras.layers import Activation, Dense, Dropout, BatchNormalization from keras.models import Sequential from keras import optimizers, callbacks from keras.utils.np_utils import to_categorical from sklearn.preprocessing import StandardScaler #-- 乱数シード np.random.seed(seed=19) tf.random.set_seed(19) #-- 標準化 sc = StandardScaler() train_X_std = sc.fit_transform(train_X) valid_X_std = sc.transform(valid_X)
モデルを作成する。
Sequential() でインスタンス化し、add メゾッドでモデルを定義する。
units がユニット数。ロジスティック回帰だと層が一つなのでここが出力層の定義になる。
input_shape が入力層で特徴量の数。
activation が活性化関数。ロジスティック回帰だとシグモイド関数。
#-- モデル model = Sequential() model.add(Dense(units=1 ,input_shape=(len(Xval),) ,activation="sigmoid"))
作成モデルをコンパイルする。
#-- コンパイル model.compile(optimizer=optimizers.SGD(lr=0.1) ,loss='binary_crossentropy' ,metrics=["accuracy"])
コンパイルしたモデルを最適化する。
callbacks.EarlyStopping で Early Stopping を実装できる。
callbacks.ModelCheckpoint('best_model.h5', save_best_only=True) でベストモデルを保存できる(後にモデルの読み込み方法を記載)。
#-- Fitting callbacks = [ callbacks.ModelCheckpoint('best_model.h5', save_best_only=True) ,callbacks.EarlyStopping(patience=10) ] history = model.fit(train_X_std, train_y ,batch_size=64 ,epochs=1000 ,verbose=1 ,callbacks=callbacks ,validation_data=(valid_X_std, valid_y))
Keras での試し書き(バリデーションデータで評価)
作成モデルで予測する。
#-- 予測 pred_y = model.predict(valid_X_std) pred_y = np.where(pred_y < 0.5, 0, 1)
重み係数を見たい場合、次で取得できる。
model.layers[0].get_weights()
今回の作成モデルを評価してみる。
ついでにsklearnで作ったロジスティック回帰を並べてみる。
from sklearn.linear_model import LogisticRegression model2 = LogisticRegression(solver='liblinear', random_state=19) model2.fit(train_X_std, train_y) pred_y2 = model2.predict(valid_X_std) pred_y2 = np.where(pred_y2 < 0.5, 0, 1)
from sklearn.metrics import classification_report, confusion_matrix print("-- keras --") print(confusion_matrix(valid_y, pred_y)) print(classification_report(valid_y, pred_y)) print() print("-- sklearn.linear_model.LogisticRegression --") print(confusion_matrix(valid_y, pred_y2)) print(classification_report(valid_y, pred_y2))

アルゴリズムが違うだろうが、だいたい同じ?
Keras での試し書き(テストデータで予測)
別セッションで作成モデルを使用したい場合、最初からPGMを再実行するのは手間。
モデルを保存してあれば load_model(パス/ファイル名) で読み込んで再利用できる。
from keras.models import load_model model3 = load_model('./best_model.h5') pred_y3 = model3.predict(test_X) pred_y3 = np.where(pred_y3 < 0.5, 0, 1)
参考
Home - Keras Documentation
Kerasによる2クラスロジスティック回帰 - 人工知能に関する断創録
本ブログで参考になりそうなもの
【統計】ロジスティック回帰分析 - こちにぃるの日記